AI Searches of the Scientific Literature to Make Discoveries in Materials Science.
The paper I'll discuss in this post is this one: Unsupervised word embeddings capture latent knowledge from materials science literature (Tshitoyan, et al, Nature 571, 95–98 (2019))
Newton's Principia lay in a drawer, the story goes, unpublished for years, until Edmond Halley, of comet fame asked Newton for help with Kepler's laws, the mathematics of which Newton had already solved. This, and not the comet, was Halley's greatest discovery, what Newton had already done but not bothered to publish.
It was entirely possible that Newton might have died with his discovery unknown, and although many facets of what he discovered might have been discovered independently, because of the basic truths behind them - Halley was himself working the problem - history would have been very different without the publication of Principia Mathematica; it is a book that changed the world.
I expect that many scientists died with potentially important work unpublished; in Newton's case, chemistry might have evolved more quickly were he not ashamed of his Alchemical work which he kept hidden.
Other works are published, forgotten and then rediscovered years after the fact and become important. Probably the most famous case was Gregor Mendel's famous work on genetics was forgotten until well after he died in 1884. His work was rediscovered by early geneticists - working without any knowledge of DNA - in the early 20th century: Happily they ultimately acknowledged his priority.
I have made it a habit over the last three decades to spend much of my free time, 5 to 10 hours a week, sometimes much more, in scientific libraries. I try to spend some, but cannot spend all of this time, in desultory reading, unconnected with my professional work.
Over the last several years I've developed a habit, probably unwise, of paying more attention to papers that are highly cited as opposed to those that aren't, particularly when I am addressing a particular question that has arisen in my mind.
Here, for instance, is an excellent paper that has only been cited by 10 people in the last 11 years: Reactor physics ideas to design novel reactors with faster fissile growth (Jagannathan et al Energy Conversion and Management Volume 49, Issue 8, August 2008, Pages 2032-2046) Four of the ten citations are the author citing himself, but only recently, in 2019, has the paper been "rediscovered."
There are certain journals that I at least scan religiously, they are overly represented in my posts on this website. There are many other journals that I wish I had time to read. There are several journals that attempt to give broad overviews, "review" journals, and even journals that solicit scientists to discuss their own work.
Here is a video by Dr. Cynthia Burrows of the University of Utah, editor of Accounts of Chemical Research giving the raison d'être for her journal, which as that scientists can simply not read all of the journals that they would like to read:
Young scientists will have tools for sorting through the prodigious scientific literature that we didn't have years ago. I remind my son of this point frequently, asking him to imagine a world without Google Scholar, Scopus, CAS and Scifinder.
Of course for a tool to be valuable, you have to
use it, which I expect he does.
This brings me to the paper I cited above, which has a very interesting approach, using lexographic programming to sort through broad swathes of the scientific literature to direct scientists to work that may be related in such a way as to allow for the discovery of new materials.
From the introduction/abstract:
The overwhelming majority of scientific knowledge is published as text, which is difficult to analyse by either traditional statistical analysis or modern machine learning methods. By contrast, the main source of machine-interpretable data for the materials research community has come from structured property databases1,2, which encompass only a small fraction of the knowledge present in the research literature. Beyond property values, publications contain valuable knowledge regarding the connections and relationships between data items as interpreted by the authors. To improve the identification and use of this knowledge, several studies have focused on the retrieval of information from scientific literature using supervised natural language processing3,4,5,6,7,8,9,10, which requires large hand-labelled datasets for training. Here we show that materials science knowledge present in the published literature can be efficiently encoded as information-dense word embeddings11,12,13 (vector representations of words) without human labelling or supervision. Without any explicit insertion of chemical knowledge, these embeddings capture complex materials science concepts such as the underlying structure of the periodic table and structure–property relationships in materials. Furthermore, we demonstrate that an unsupervised method can recommend materials for functional applications several years before their discovery...
...Assignment of high-dimensional vectors (embeddings) to words in a text corpus in a way that preserves their syntactic and semantic relationships is one of the most fundamental techniques in natural language processing (NLP). Word embeddings are usually constructed using machine learning algorithms such as GloVe13 or Word2vec11,12, which use information about the co-occurrences of words in a text corpus. For example, when trained on a suitable body of text, such methods should produce a vector representing the word ‘iron’ that is closer by cosine distance to the vector for ‘steel’ than to the vector for ‘organic’. To train the embeddings, we collected and processed approximately 3.3 million scientific abstracts published between 1922 and 2018 in more than 1,000 journals deemed likely to contain materials-related research, resulting in a vocabulary of approximately 500,000 words. We then applied the skip-gram variation of Word2vec, which is trained to predict context words that appear in the proximity of the target word as a means to learn the 200-dimensional embedding of that target word, to our text corpus (Fig. 1a). The key idea is that, because words with similar meanings often appear in similar contexts, the corresponding embeddings will also be similar...
...For example, many words in our corpus represent chemical compositions of materials, and the five materials most similar to LiCoO2 (a well-known lithium-ion cathode compound) can be determined through a dot product (projection) of normalized word embeddings. According to our model, the compositions with the highest similarity to LiCoO2 are LiMn2O4, LiNi0.5Mn1.5O4, LiNi0.8Co0.2O2, LiNi0.8Co0.15Al0.05O2 and LiNiO2—all of which are also lithium-ion cathode materials.
Some pictures from the text:
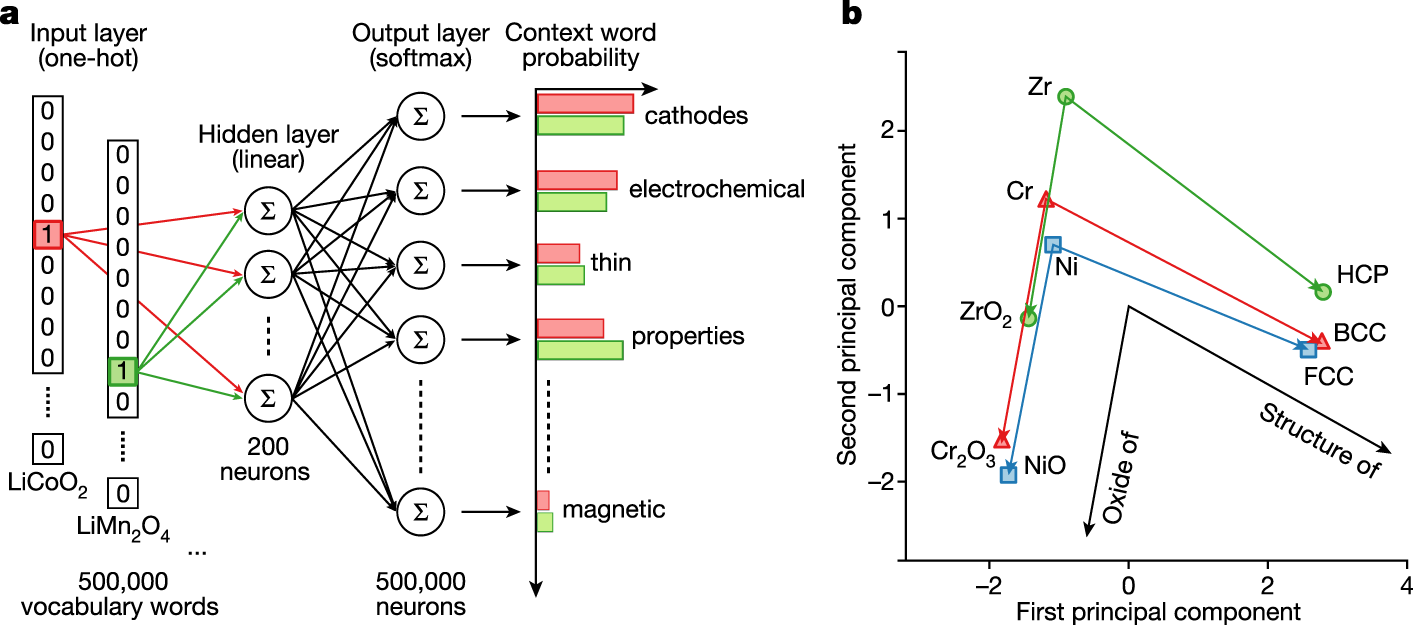
The caption:
a, Target words ‘LiCoO2’ and ‘LiMn2O4’ are represented as vectors with ones at their corresponding vocabulary indices (for example, 5 and 8 in the schematic) and zeros everywhere else (one-hot encoding). These one-hot encoded vectors are used as inputs for a neural network with a single linear hidden layer (for example, 200 neurons), which is trained to predict all words mentioned within a certain distance (context words) from the given target word. For similar battery cathode materials such as LiCoO2 and LiMn2O4, the context words that occur in the text are mostly the same (for example, ‘cathodes’, ‘electrochemical’, and so on), which leads to similar hidden layer weights after the training is complete. These hidden layer weights are the actual word embeddings. The softmax function is used at the output layer to normalize the probabilities. b, Word embeddings for Zr, Cr and Ni, their principal oxides and crystal symmetries (at standard conditions) projected onto two dimensions using principal component analysis and represented as points in space. The relative positioning of the words encodes materials science relationships, such that there exist consistent vector operations between words that represent concepts such as ‘oxide of’ and ‘structure of’.

The caption:
a, A ranking of thermoelectric materials can be produced using cosine similarities of material embeddings with the embedding of the word ‘thermoelectric’. Highly ranked materials that have not yet been studied for thermoelectric applications (do not appear in the same abstracts as words ‘ZT’, ‘zT’, ‘seebeck’, ‘thermoelectric’, ‘thermoelectrics’, ‘thermoelectrical’, ‘thermoelectricity’, ‘thermoelectrically’ or ‘thermopower’) are considered to be predictions that can be tested in the future. b, Distributions of the power factors computed using density functional theory (see Methods) for 1,820 known thermoelectrics in the literature (purple) and 7,663 candidate materials not yet studied as thermoelectric (green). Power factors of the first ten predictions not studied as thermoelectrics in our text corpus and for which computational data are available (Li2CuSb, CuBiS2, CdIn2Te4, CsGeI3, PdSe2, KAg2SbS4, LuRhO3, MgB2C2, Li3Sb and TlSbSe2) are shown with black dashed lines. c, A graph showing how the context words of materials predicted to be thermoelectrics connect to the word thermoelectric. The width of the edges between ‘thermoelectric’ and the context words (blue) is proportional to the cosine similarity between the word embeddings of the nodes, whereas the width of the edges between the materials and the context words (red, green and purple) is proportional to the cosine similarity between the word embeddings of context words and the output embedding of the material. The materials are the first (Li2CuSb), third (CsAgGa2Se4) and fourth (Cu7Te5) predictions. The context words are top context words according to the sum of the edge weights between the material and the word ‘thermoelectric’. Wider paths are expected to make larger contributions to the predictions. Examination of the context words demonstrates that the algorithm is making predictions on the basis of crystal structure associations, co-mentions with other materials for the same application, associations between different applications, and key phrases that describe the material’s known properties.

The caption:
a, Results of prediction of thermoelectric materials using word embeddings obtained from various historical datasets. Each grey line uses only abstracts published before that year to make predictions (for example, predictions for 2001 are performed using abstracts from 2000 and earlier). The lines plot the cumulative percentage of predicted materials subsequently reported as thermoelectrics in the years following their predictions; earlier predictions can be analysed over longer test periods, resulting in longer grey lines. The results are averaged (red) and compared to baseline percentages from either all materials (blue) or non-zero DFT bandgap27 materials (green). b, The top five predictions from the year 2009 dataset, and evolution of their prediction ranks as more data are collected. The marker indicates the year of first published report of one of the initial top five predictions as a thermoelectric.
(I have personally been very interested in thermoelectrics because of their potential to produce electricity, free of mechanical systems from the heat of used nuclear fuels, and heat transfer lines during rejection of heat to the environment, raising the thermodynamic efficiency as well as doing things like engineering away the potential for another event like Fukushima.)
From the conclusion of the paper:
Scientific progress relies on the efficient assimilation of existing knowledge in order to choose the most promising way forward and to minimize re-invention. As the amount of scientific literature grows, this is becoming increasingly difficult, if not impossible, for an individual scientist. We hope that this work will pave the way towards making the vast amount of information found in scientific literature accessible to individuals in ways that enable a new paradigm of machine-assisted scientific breakthroughs.
Cool paper, I think.
A very different approach to knowledge, rediscovering that which already exists.
Have a nice weekend.